
发现搜索引擎是个神奇的东西,偶然想起的关…
发现搜索引擎是个神奇的东西,偶然想起的关…

最近开始阅读一本关于机器学习的新书,分享…

最近又搜索了下SNP imputatio…
在读取一行数据之前,应该先考虑下重复数据…

1.《高效R语言编程》笔记 2.&nbs…
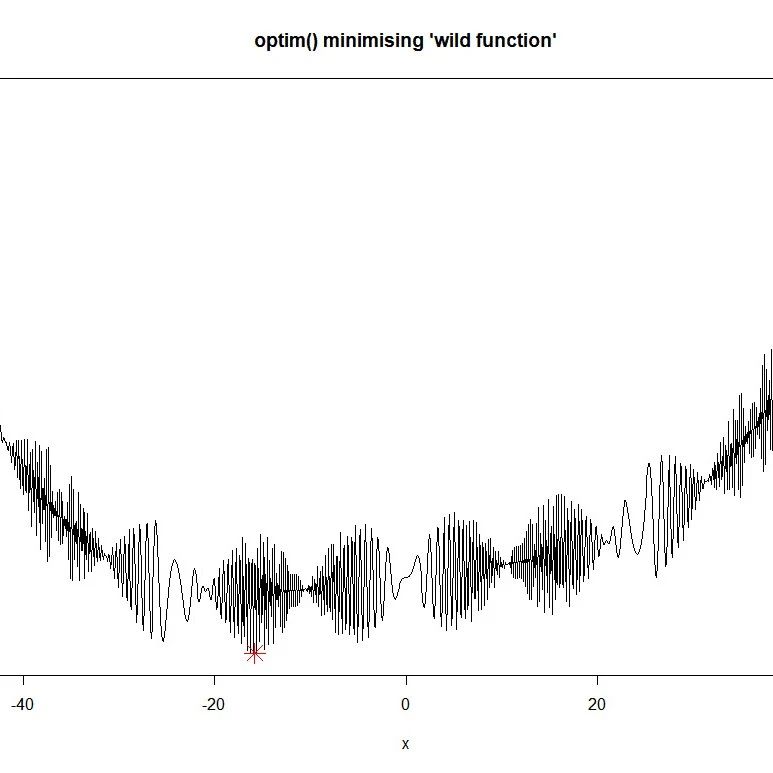
软件配置 本章主要是代码标准与技术的内容…

软件配置 benchmarkme包 高效…

软件配置 需要使用C++编译器,安装方法…

将你的数据整理好是一个可敬的、某些情况下…

最近又搜索了下基因型填充的相关内容,之前…