3.摸索
把fastq和fastq.gz数据放在工作文件夹q2studio并不识别,也可能是我的文件命名规律不符合软件的识别规律,不管怎样,为了尝试下图形界面,还是把数据导入qiime做成qza格式试试吧,有点无奈,还是回到了命令行。这个按我上次的那个python脚本解决,https://jiawen.zd200572.com/278.html 。
然后,q2studio识别了数据,于是,好几个插件里的东西变的可用了。于是开始一段美好的探险旅程吧(就按Moving Pictures这个步骤走一遍)!

3.1 拆分结果统计
由于我这里是拆分好的数据,跳过拆分barcode的步骤,查看测序数据质量和各样本数据情况。很简单,就是demux插件下的 summarize选项。
然后就可以愉快地查看结果了:
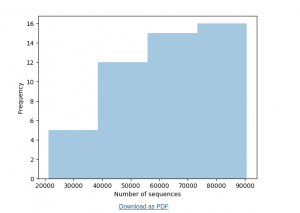
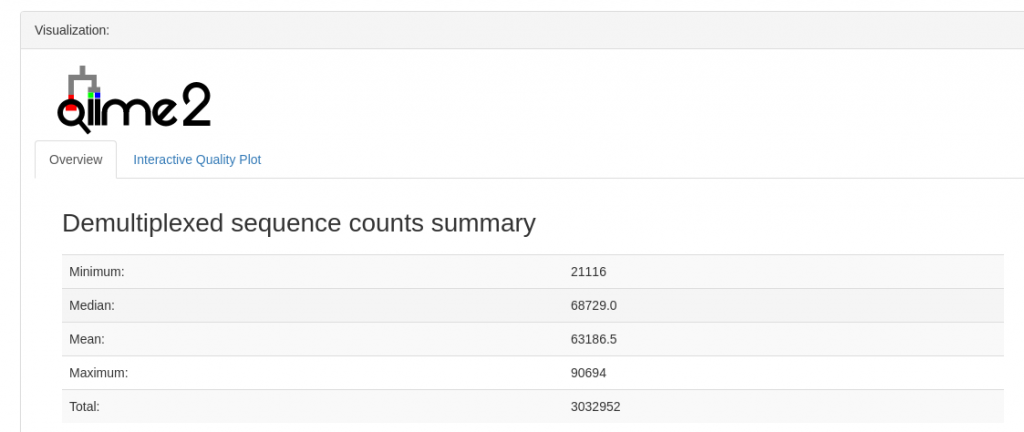
然后质量分布情况,和命令行版本是一模一样的,只不过不需要命令选中就可以查看:
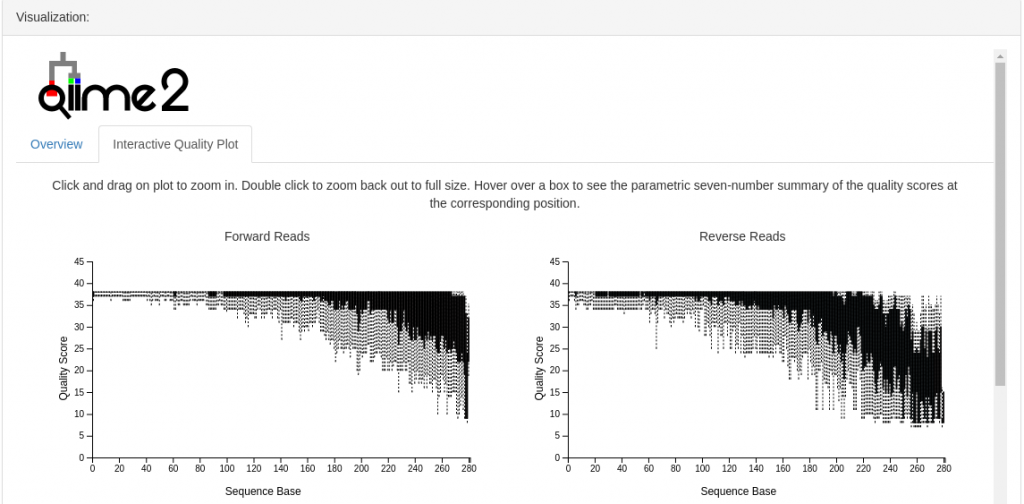
从上面右边的图中可以看出反向测序质量偏低,要去掉260以后的部分(平均质量值低于20)。
3.2 序列质控和生成OTU表
质量过滤只有一个插件是可用的,于是就用这个了,参数用最低质量值20,以3为窗口,0.75阀值试下。

大概是性能比较差了,已经过去了20min,还是没有反应的样子,30min终于结束了,继续。
进入DADA2插件,这个用的人多,就用它了,好吧,因为虚拟电脑只有两核心,有得等了,之前36线程服务器还需要半小时以上。
chimera_method: consensus hashed_feature_ids: true max_ee: 2 min_fold_parent_over_abundance: 1 n_reads_learn: 1000000 n_threads: 2 trim_left_f: 0 trim_left_r: 0 trunc_len_f: 0 trunc_len_r: 260 trunc_q: 2