将你的数据整理好是一个可敬的、某些情况下是至关重要的技能,所以作者使用了数据木匠这个词。这是本书最重要的一章,将涉及以下内容:
-
使用tidyr整理数据 -
使用dplyr处理数据 -
使用数据库 -
使用data.table处理数据
软件配置
library("tibble")
library("tidyr")
library("stringr")
library("readr")
library("dplyr")
library("data.table")
高效的tibble包
tibble定义了新的数据框,更加易用。
-
tibble会打印每个变量的类,data.frame不会 -
stringAsFactors默认不转换 -
输出时,只输出前10行
使用tidyr与正则表达式整理数据
整理数据包括数据清理和数据重构,前者是重定格式与标记脏数据,stringi和stringr可以通过正则表达式更新脏字符串,assertive和assertr包可以在数据分析项目的一开始进行数据完整性的校验。通常的数据清理是将非标准文本字符串转换成lubridate简介所描述的数据格式。vignette("lubridate") 整洁是个广泛的概念,也包括重构数据,以便有利于数据分析和建模。R语言运行几个长列比运行一些短列快,所以一般认为宽数据(不整洁),长数据(整洁)。
整洁是个广泛的概念,也包括重构数据,以便有利于数据分析和建模。R语言运行几个长列比运行一些短列快,所以一般认为宽数据(不整洁),长数据(整洁)。
tidyr方便了收集与分割两个常见的操作
gather()收集是将列名换成新变量,将宽表变成长表,spread()是实现相反过程的函数。用法是:gather(data,key,value,-religion),分别是数据框,要转换成分类的列名,单元值的列名和清除收集的变量
使用seperate()分割联合变量
分割是指将一个实际由两个变量组成的变量分割成两个独立列
library(tidyr)
agesex <- c("m0-10","f0-10")
n <- c(3,5)
agesex_df <- tibble(agesex,n)
# A tibble: 2 x 2
agesex n
<chr> <dbl>
1 m0-10 3
2 f0-10 5
separate(agesex_df,col=agesex,into=c("age","sex"))
# A tibble: 2 x 3
age sex n
<chr> <chr> <dbl>
1 m0 10 3
2 f0 10 5
其他tidyr函数
broom包提供了模型结果的标准输出格式bit.ly[1] P.s,不知道为啥,这网站还得过墙,难道这是架设在了谷哥的服务器上。 使用broom::tidy()广泛应用于模型数据,并以标准数据框格式返回模型输出。使用变量名非标准化求值更高效,见R语言 dplyr传递参数_自由 平等~忠诚 奉献-CSDN博客[2]。只是函数名多了个下划线那么简单吗?
使用broom::tidy()广泛应用于模型数据,并以标准数据框格式返回模型输出。使用变量名非标准化求值更高效,见R语言 dplyr传递参数_自由 平等~忠诚 奉献-CSDN博客[2]。只是函数名多了个下划线那么简单吗?
正则表达式
R与stringr分别使用grepl()和str_detect()来进行,我比较喜欢基础R的,不知你喜欢安装包还是用基本的。
使用dplyr高效处理数据
这个包名的意思是数据框钳,相比基础R的优点是运行更快、与整洁数据和数据库配合好。函数名的部分灵感来自SQL。 与基本R中类似函数不同,变量无需使用 $ 操作符就可直接使用,设计与magrittr包的%>%管道操作符一起使用,以允许每个数据阶段写成新的一行。其是一个大型包,本身可以看成一门语言。
与基本R中类似函数不同,变量无需使用 $ 操作符就可直接使用,设计与magrittr包的%>%管道操作符一起使用,以允许每个数据阶段写成新的一行。其是一个大型包,本身可以看成一门语言。
列改名
rename(),使用反引号‘`’包裹,允许R使用不规范的列名。
改变列的分类
R对象的类是性能的关键,as.numeric()、data.matrix()等改变类,或者vapply(data, class,chracter(1))。unlist()函数的作用,就是将list结构的数据,变成非list的数据,即将list数据变成字符串向量或者数字向量的形式。
滤除行
filter() ## 键操作
数据聚合
基于组合变量生成数据汇总,以前称为split-apply-combine。summarize是一个多面手,用于返回自定义范围的汇总统计值。
非标准计算
代码中没有引号包裹的原始名字,这种方式叫做非标准计算(NSE),高效交互使用函数,减少键盘输入,允许Rstudio中自动完成。还是函数名多个_。
合并数据集
# 安装包
install.packages("ggmap","maps")
library(ggmap)
world <- map_data("world")
names(world)
# [1] "long" "lat" "group" "order" "region"
[6] "subregion"
# 使用数据库 R会把所有数据加载到内存中,数据库是从硬盘中获取数据的。RODBC是一个资深包,提供R与SQL server的接口。DBI包提供了通用接口与驱动程序的类集,如RSQLITE,是访问数据库的统一框架,允许其他驱动程序以模块包添加。这里建议不要把数据库密码和API密钥等放在命令中,而要放大.Renviron文件中。dbConnect()函数连接数据库,dbSendQuery()查询,dbFetch()加载到R中。mongolite包可以连接MongoDB,MonetDB也可以。
数据库与dplyr
必须使用src_*()函数创建一个数据源。# 使用data.table()处理数据 是dplyr的替代,两个哪个好存在争议,最好学一个一直坚持下去。如果两个都是新手,推荐dplyr。为了提升性能,可以设置键,类似数据库的主键,方便二进制算法提取目标子集行。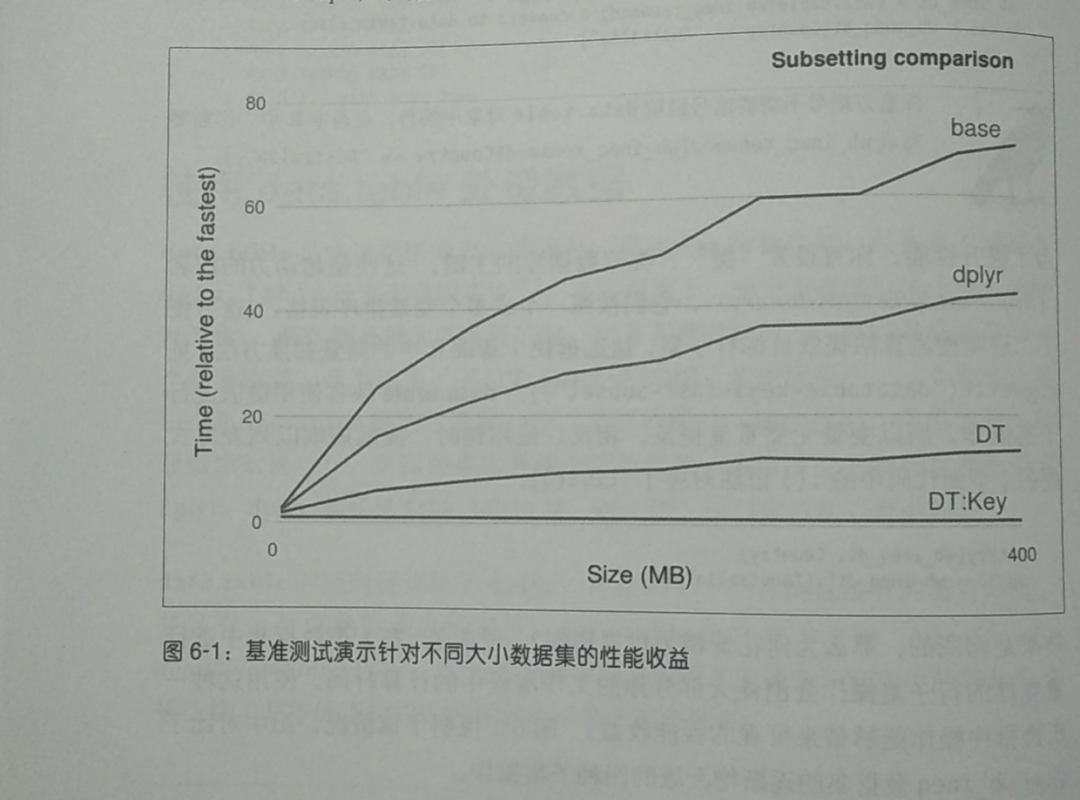
参考资料
bit.ly: http://bit.ly/broomvignette
[2]R语言 dplyr传递参数_自由 平等~忠诚 奉献-CSDN博客: https://blog.csdn.net/tanzuozhev/article/details/50597233
本篇文章来源于微信公众号: 微因