前面我们探索了处理不能拼接的V4 PE150数据,首先双向reads根据质量情况分别切成120bp,然后使用dada2 R包进行了直接+10N拼接,生成ASV表,再分别使用dada2包,decipher包和qiime2进行了物种注释,基本上完成了一个最简单的分析过程。这里填下自己之前挖的坑,比较一下这个含有348条序列的样本,qiime2,dada2和的分类器哪个效果更好。
界门纲目科
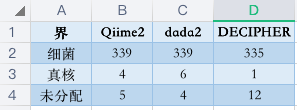
只是简单看下分类到某个种类的数目差别。在界(kingdom)这个级别,差别还好(如下图所示),如果差别大才有问题呢!
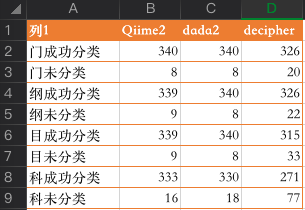
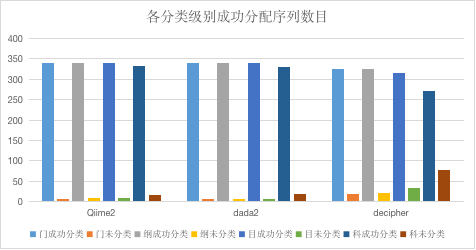
在门、纲、目和科级别,qiime2和dada2表现相似,decipher表现有些差强人意了。根据这个结果,我认为手上这个数据不适合使用decipher进行物种注释。
属种级别
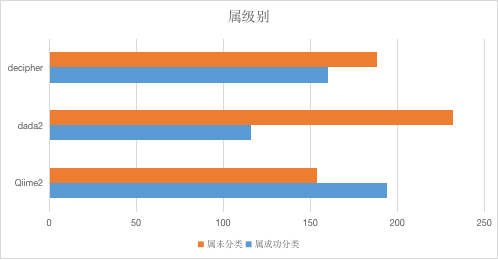
在属一级,这一般是我们短读长测序16S分析最需要的一级,差别就更加明显了,Qiime2的物种注释依然优势满满。

在种的级别上,dada2教程上说物种注释可以使用以种训练的模型,更为准确,之前是尝试了的,由于手上的序列拼接中间含有10个N,没法注释到属,会报错。所以除去Qiime2有75个注释到种外,其实两个方法是没有到种的。当然,这么短的读长下,到种的准确性有的也是存疑问的。
这里,我们完成了物种注释的结果比较,前面已经进行的探索有: