最近偶尔探索下GPU生信软件,虽然方兴未艾,发现多数软件已经是古董,比如GPU版本的Blast,使用CUDA7,10.1这样的版本已经是最新的,软件依赖复杂,编译较难成功(亲测失败)。当然,服务器的软件版本一般是相对稳定的,可能用起来问题也不大。
我想这里面一个是硬件原因,只有事实垄断的英伟达拥有CUDA生态,而且像苹果一样拒绝开源,兼容性差,另外就是软件开发人员一般只是为了做个课题,没有持续的软件更新,软件也不会有很多人使用啦。相信未来,国产的GPU算力卡生态的崛起,以及开源社区的努力,会让这种情况得到改观,未来不能在一家公司身上,未来,需要一个联盟。
书归正传,今天分享一个早在2015年就发表的短reads比对软件Arioc,由大名鼎鼎的约翰霍普金斯大学计算生物学中心开发,BSD证书上,值得分享的一点是它是持续更新的,相对好安装,能适应今天的软硬件环境。下面,我们来看下软件的一些情况:
软件简介
Arioc是一个GPU加速的DNA短读比对器,用于WGS和WGBS的reads,具有高通量(4 GPU计算机上150 – 200万人类参考基因组测序reads/s),非常适合大规模的NGS数据处理。软件是用C++编写的,支持Nvidia CUDA环境,无论是Windows还是Linux系统都能运行。只要你的电脑有足够的内存和至少一块Nvidia GPU,就能轻松安装Arioc。
精准与高效:Arioc使用了Smith-Waterman算法,在处理含有多个插入和删除的读序列时,能够找到更好的映射。而且在保持功能性和准确性的同时,速度提升很大!
灵活性与可调性:Arioc提供了多种用户可配置参数,可以根据具体的硬件和数据分析需求来优化性能。无论是追求速度还是灵敏度,Arioc都能满足。
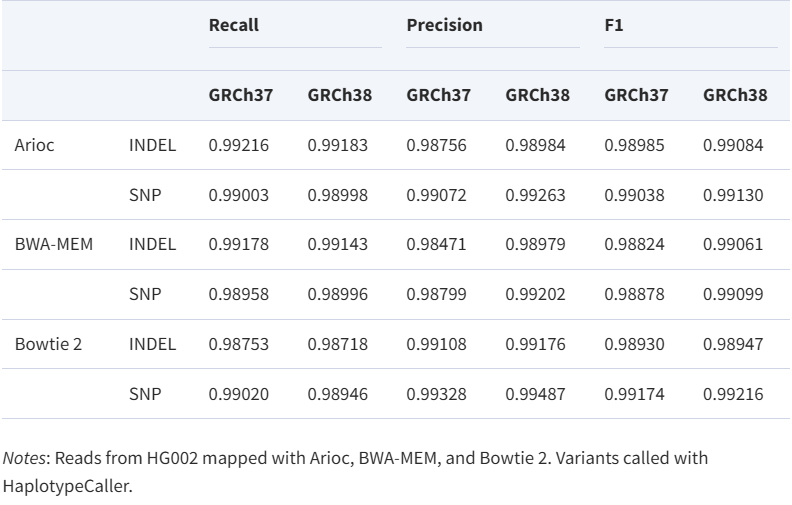
软件的表现(10.1093/bioinformatics/btad480)
特色功能
-
AriocE、AriocU和AriocP:分别负责编码序列数据、比对未配对读序列和比配对端读序列。
-
支持多种格式:接受FASTA格式的参考基因组序列和FASTQ格式的reads序列,生成SAM格式的输出。
-
数据库友好:Arioc还能创建适用于Microsoft SQL Server高速“批量”输入的二进制数据格式文件。
最初注意到这个软件是看到一个甲基化的GPU分析流程,这个软件最初2015年发表于PeerJ,2018年在Bioinformatics上发表了甲基化的版本,2020年在PLOS COMPUTATIONAL BIOLOGY发表了使用多GPU分析的成果。



软件github地址是:https://github.com/RWilton/Arioc
软件安装
以WSL2的Ubuntu 22.04系统为例,
# 使用加速镜像下载软件源码
wget ghgo.xyz/https://github.com/RWilton/Arioc/releases/download/v1.52/Arioc.x.152.zip
# 解压
unzip Arioc.x.152.zip
# 清理
make clean
# 编译前准备,使用gcc9,因为gcc10+报错
sudo apt install gcc-9 g++-9-y
# 修改默认gcc, g++链接
sudomv /usr/bin/gcc /usr/bin/gcc.bak
sudoln-s /usr/bin/gcc-9 /usr/local/bin/gcc
sudomv /usr/bin/g++ /usr/bin/g++.bak
sudoln-s /usr/bin/g++-9 /usr/local/bin/g++
# 编译
make AriocP releaseCUDA_CC=80CUDA_PATH=/usr/local/cuda-11.3/-j17
make AriocE releaseCUDA_CC=80CUDA_PATH=/usr/local/cuda-11.3/-j17
make AriocU releaseCUDA_CC=80CUDA_PATH=/usr/local/cuda-11.3/-j17
好啦,这样就安装完成啦!
软件测试
这里就使用官方的示例数据进行啦!编码这步主要是CPU进行的,大概需要32G RAM,我用swap扛的,速度还算可以。
# 测试下来需要的显存应该是在10G+的,否则会报错,感谢师兄友情赞助的显卡
# 下载示例数据
wget https://github.com/RWilton/Arioc/releases/download/v1.52/Arioc.RQA.152.zip
# 解压
unzip Arioc.RQA.152.zip
# 编码参考基因组
cd R/S_cerevisiae/
../../AriocE AriocE.gapped.cfg
../../AriocE AriocE.nongapped.cfg
cd ../../Q/S_cerevisiae/
# 编码fastq
../../AriocE AriocE.paired.cfg
../../AriocE AriocE.unpaired.cfg
cd ../../A/S_cerevisiae/
# 比对
../../AriocP AriocP.paired.cfg
../../AriocU AriocU.unpaired.cfg
AriocBase::releaseGpuResources: GPU LUT unload complete in 3336ms
配置文件指定了GPU设备、批处理大小、种子类型、评分参数以及输入输出文件路径,配置文件示例:
<?xmlversion="1.0" encoding="utf-8"?>
<!-- AriocE.paired.cfg
-->
<AriocE>
<dataInsequenceType="Q"srcId="1"QNAME="(*.*) */*">
<filesubId="1"mate="1">./raw/SRR3203167_1.250k.fastq</file>
<filesubId="1"mate="2">./raw/SRR3203167_2.250k.fastq</file>
</dataIn>
<dataOut>
<path>./enc.paired</path>
</dataOut>
</AriocE>
总结,属于建索引3分钟,比对比建索引时间还短的体会,学习曲线还是有一点的,需要一些适应。
如果需要cuda11.*版本的二进制文件,可以后台回复“Arioc”,分享给大家。
展望
相信随着大模型及Agent的发展,近期可以是生信分析员的agent可以解放许多烦索的工作,人更多地可以花时间进行监督已有流程的运行,错误的改正。远期是类似AutoBA的全自动生信agent,自动流程构建和数据分析。当然不排除可以部分流程的一步到位,或许未来一段时间还是人和AI相互配合解决具体问题。
本篇文章来源于微信公众号:微因